Phương pháp lai giữa học máy và thống kê để dự báo tiêu thụ năng lượng ngắn hạn trong các tòa nhà dân cư
A Hybrid machine learning–statistical based method for short-term energy consumption prediction in residential buildings
| Tác giả | Kamran Hassanpouri Baesmat
Emma E. Regentova Yahia Baghzouz |
| Ngày đăng tải | 09/07/2025 |
| DOI | https://doi.org/10.1016/j.egyai.2025.100552 |
| Nguồn bài nghiên cứu | Science Direct |
| Từ khóa | Học máy
Dự báo phụ tải điện Phân tích thống kê Tiêu thụ năng lượng Lưới điện Trí tuệ nhân tạo Dự báo phần dư |
1 – GIỚI THIỆU
Sự gia tăng dân số và phát triển công nghiệp đã khiến nhu cầu năng lượng toàn cầu liên tục tăng. Do đó, việc dự báo chính xác phụ tải điện trở thành một yêu cầu cấp thiết nhằm đảm bảo vận hành hiệu quả, tăng cường độ tin cậy của lưới điện và hỗ trợ các hoạt động như bảo trì dự đoán, định giá điện và phân bổ tài nguyên. Dự báo phụ tải được phân loại thành ba nhóm: dài hạn (LTLF), trung hạn (MTLF) và ngắn hạn (STLF). Trong đó, STLF là trọng tâm của nghiên cứu này, vì nó dự đoán nhu cầu năng lượng trong khung thời gian ngắn (dưới một tuần), giúp tối ưu hóa phân phối điện năng hàng ngày.
Tuy nhiên, độ chính xác của dự báo bị ảnh hưởng lớn bởi chất lượng dữ liệu, các yếu tố biến thiên như thời tiết, hành vi tiêu dùng và tính phi tuyến trong dữ liệu. Các phương pháp thống kê truyền thống như ARIMA, SARIMA đã chứng minh được hiệu quả trong nhiều bối cảnh nhưng hạn chế trong việc xử lý quan hệ phi tuyến. Song song đó, các kỹ thuật học máy như Random Forest, LSTM hay CNN đã cho thấy tiềm năng nhưng lại gặp khó khăn về chi phí tính toán, khả năng khái quát hóa và tính diễn giải.
Để khắc phục hạn chế này, nghiên cứu đề xuất một phương pháp lai kết hợp mô hình thống kê tham số (SARIMAX) và các thuật toán học máy (Random Forest, XGBoost, LSTM) cùng với bước hiệu chỉnh sai số dư (Remainder Prediction – RP). Phương pháp này hướng đến việc tận dụng ưu điểm của cả hai nhóm: thống kê để xử lý xu hướng tuyến tính và mùa vụ, học máy để khai thác mối quan hệ phi tuyến phức tạp, đồng thời bổ sung bước dự báo phần dư nhằm giảm thiểu sai số tích lũy.
2 – MÔ TẢ HỆ THỐNG
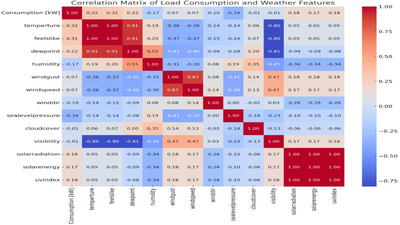
Bộ dữ liệu được sử dụng gồm số liệu tiêu thụ điện năng trong một hộ gia đình tại Summerlin, Las Vegas (Mỹ) năm 2022, thu thập liên tục mỗi 5 phút. Dữ liệu không có giá trị bị thiếu, bao gồm phụ tải của nhiều thiết bị như điều hòa, tủ lạnh, lò vi sóng, máy giặt/sấy, v.v. Ngoài ra, 17 đặc trưng thời tiết (nhiệt độ, độ ẩm, áp suất khí quyển, bức xạ mặt trời, gió, v.v.) được thu thập từ Visual Crossing.
Trong giai đoạn tiền xử lý, nhóm tác giả tính toán hệ số ngày lễ (holiday coefficient), điều chỉnh mùa vụ bằng cách chuẩn hóa độ dài tháng về 31 ngày, và áp dụng nhiều kỹ thuật chọn đặc trưng (ma trận tương quan, ANOVA, MRMRMS, kiểm định Chi-Square). Kết quả cho thấy bốn đặc trưng quan trọng nhất ảnh hưởng đến tiêu thụ năng lượng là: áp suất mực nước biển, nhiệt độ, nhiệt độ cảm nhận và điểm sương.
3 – PHƯƠNG PHÁP NGHIÊN CỨU
Phương pháp đề xuất có tên SSRXLR gồm 2 giai đoạn:
Giai đoạn 1 – Dự báo sơ cấp (SSRXL): sử dụng tổ hợp bốn mô hình SARIMAX, Random Forest, XGBoost, và LSTM. Mỗi mô hình được huấn luyện riêng biệt để khai thác các khía cạnh khác nhau (SARIMAX xử lý xu hướng và mùa vụ, RF/XGBoost mô hình hóa quan hệ phi tuyến giữa biến thời tiết và tiêu thụ điện, LSTM nắm bắt phụ thuộc theo chuỗi thời gian). Kết quả được kết hợp bằng phương pháp trung bình để tạo dự báo ban đầu.
Giai đoạn 2 – Hiệu chỉnh sai số dư (RP): sai số giữa giá trị dự báo và thực tế được phân tích. Bước này áp dụng biến đổi wavelet để khử nhiễu, sau đó mô hình Grey-Markov cùng với SARIMA, RF, LSTM được dùng để dự báo phần dư. Dự báo cuối cùng được hình thành bằng cách cộng phần dư dự báo vào kết quả dự báo sơ cấp.
Quy trình được đánh giá bằng nhiều chỉ số: MAE, RMSE, MAPE, RMSLE và hệ số xác định R².
4 – KẾT QUẢ NGHIÊN CỨU
Phương pháp SSRXLR cho kết quả vượt trội so với các mô hình tham chiếu (Linear Regression, Decision Tree, Random Forest, Support Vector Machine, LSTM, GRU, DBN, SARIMAX, XGBoost). Cụ thể:
Hệ số xác định R² đạt 0,97, cao hơn so với Random Forest (0,92) và SARIMAX (0,67).
Sai số RMSLE của SSRXLR chỉ 0,043, thấp hơn đáng kể so với Random Forest (0,109) và SARIMAX (0,149).
Kết quả cho thấy bước hiệu chỉnh sai số dư giúp mô hình vừa giảm thiểu sai số, vừa dự đoán đúng cả chiều hướng của sai số (hệ số tương quan Pearson giữa sai số thực và sai số dự báo đạt 0,9878).
Ngoài ra, phương pháp còn chứng minh tính ứng dụng thực tiễn khi giúp lưới điện cải thiện lập kế hoạch phụ tải đỉnh, đấu giá biểu giá, giảm yêu cầu công suất dự phòng và hỗ trợ tích hợp năng lượng tái tạo.
5 – KẾT LUẬN
Nghiên cứu đã phát triển một phương pháp lai mới, kết hợp các mô hình thống kê và học máy nhằm nâng cao độ chính xác trong dự báo phụ tải ngắn hạn. Bằng việc chọn lọc đặc trưng tối ưu (nhiệt độ, áp suất, nhiệt độ cảm nhận và điểm sương), chuẩn hóa dữ liệu mùa vụ, tính hệ số ngày lễ và bổ sung bước hiệu chỉnh sai số dư, phương pháp SSRXLR đã đạt hiệu suất vượt trội so với nhiều kỹ thuật tiên tiến hiện hành.
Phương pháp này không chỉ mang lại lợi ích khoa học mà còn có giá trị ứng dụng cao trong vận hành lưới điện thông minh, quản lý năng lượng và hoạch định tài nguyên. Tuy nhiên, thách thức chính là chi phí tính toán và yêu cầu chuyên môn cao trong triển khai. Nghiên cứu mở ra triển vọng phát triển các mô hình lai có khả năng mở rộng, thích ứng với nhiều bối cảnh tiêu thụ năng lượng khác nhau và hỗ trợ tối ưu hóa vận hành hệ thống điện trong tương lai.





