Kho lưu trữ rủi ro AI: Một đánh giá tổng quan, cơ sở dữ liệu và phân loại các rủi ro từ trí tuệ nhân tạo
The AI risk repository: A meta-review, database, and taxonomy of risks from artificial intelligence
| Tác giả |
Peter Slattery Alexander K. Saeri Emily A.C. Grundy Jess Graham Michael Noetel Risto Uuk James Dao Soroush Pour Stephen Casper Neil Thompson |
| Ngày đăng tải | 08/05/2026 |
| DOI | https://doi.org/10.1016/j.patter.2026.101517 |
| Nguồn bài nghiên cứu | Science Direct |
| Từ khóa |
Trí tuệ nhân tạo Rủi ro trí tuệ nhân tạo Phân loại rủi ro Cơ sở dữ liệu rủi ro Khung rủi ro Quản trị trí tuệ nhân tạo |
1 – GIỚI THIỆU
Trí tuệ nhân tạo (AI) đang định hình lại toàn bộ xã hội, từ việc tạo video, chẩn đoán y tế, các tác nhân lập trình cho đến các phương tiện tự hành, tuy nhiên các nhà nghiên cứu, nhà hoạch định chính sách và các công ty công nghệ vẫn đang thiếu một hệ thống thuật ngữ chung để thảo luận về các rủi ro của AI. Hiện trạng này dẫn đến sự đa dạng quá mức về các khung đánh giá, gây ra sự nhầm lẫn về mặt khái niệm khi cùng một thuật ngữ lại được sử dụng để mô tả các vấn đề khác nhau, hoặc các từ khác nhau lại được dùng để chỉ những mối quan ngại giống hệt nhau. Sự phân mảnh này tạo ra những rào cản lớn đối với việc so sánh chéo giữa các nghiên cứu, đồng thời cản trở các nỗ lực ứng phó phối hợp đối phó với những thách thức do công nghệ mới nổi mang lại. Để giải quyết rào cản này, nghiên cứu đã tạo ra Kho lưu trữ rủi ro AI (AI Risk Repository), một cơ sở dữ liệu toàn diện và có tính cập nhật liên tục bao gồm 1.725 rủi ro được trích xuất từ 74 khung và hệ thống phân loại hiện có. Việc thiết lập một điểm tham chiếu chung này cung cấp một nền tảng thống nhất, cho phép các bên liên quan từ các nhà phát triển, kiểm toán viên đến các cơ quan quản lý áp dụng các cách tiếp cận toàn diện và phối hợp tốt hơn trong việc thảo luận, nghiên cứu và quản trị các hệ thống AI trên nhiều lĩnh vực và khu vực pháp lý khác nhau, đảm bảo xã hội có thể quản lý rủi ro trong khi hiện thực hóa các lợi ích mà AI mang lại.
2 – MÔ TẢ HỆ THỐNG
Hệ thống lưu trữ và phân loại rủi ro AI được xây dựng dựa trên hai hệ thống phân loại bổ trợ cho nhau nhằm đánh giá rủi ro từ cả góc độ nguyên nhân phát sinh lẫn góc độ hậu quả tác động trong thực tế. Hệ thống thứ nhất là Phân loại Nguyên nhân (Causal Taxonomy), có nhiệm vụ nắm bắt các điều kiện tiền đề dẫn đến rủi ro dựa trên ba tiêu chí cốt lõi: Thực thể (Entity), Ý định (Intent) và Thời điểm (Timing). Tiêu chí “Thực thể” xác định xem rủi ro do quyết định và hành động của con người gây ra, do bản thân hệ thống AI tự định đoạt, hay là kết quả của quá trình tương tác phức tạp giữa con người và máy tính. Tiêu chí “Ý định” phân biệt rõ ràng giữa việc rủi ro xuất hiện như một kết quả đã được dự kiến khi theo đuổi một mục tiêu (cố ý), hay nó xảy ra ngoài dự kiến (vô ý). Tiêu chí “Thời điểm” quy định giai đoạn phát sinh trong vòng đời phát triển, phân định xem rủi ro xảy ra trước khi triển khai (trong quá trình thiết kế, huấn luyện) hay sau khi mô hình đã được triển khai và đưa vào sử dụng thực tế.
Hệ thống phân loại thứ hai là Phân loại Miền (Domain Taxonomy), tập trung vào các hậu quả thực tế, hệ thống hóa các mối nguy hại và thiệt hại vào bảy lĩnh vực tác động xã hội lớn bao gồm 24 lĩnh vực phụ. Các lĩnh vực chính này trải dài qua các vấn đề cốt lõi như sự phân biệt đối xử và nội dung độc hại; vi phạm quyền riêng tư và lỗ hổng bảo mật; sự lan truyền thông tin sai lệch; các hành động lạm dụng của tác nhân độc hại; những hệ lụy trong tương tác giữa con người và máy tính; các tác hại đối với kinh tế xã hội và môi trường; và cuối cùng là các vấn đề liên quan đến giới hạn, lỗi hệ thống và độ an toàn nội tại của chính AI. Điểm đặc biệt của hệ thống Phân loại Miền là các danh mục không loại trừ lẫn nhau một cách tuyệt đối, bởi trên thực tế, một rủi ro duy nhất như việc AI tạo ra thông tin xuyên tạc hoàn toàn có thể vừa thuộc miền thông tin sai lệch, vừa được xếp vào miền lạm dụng bởi các tác nhân độc hại. Thông qua sự kết hợp của hai hệ thống này, Kho lưu trữ cung cấp một lăng kính kép để các nhà phát triển và nhà quản lý có thể phân tách chi tiết mọi rủi ro, từ nguồn gốc sâu xa cho đến hệ lụy đa chiều mà chúng mang lại.
3 – PHƯƠNG PHÁP NGHIÊN CỨU
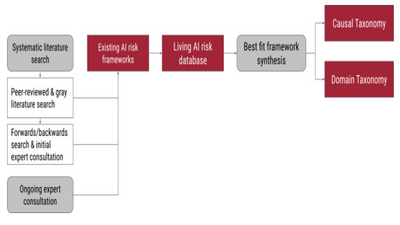
Nghiên cứu áp dụng quy trình đánh giá hệ thống bài bản dựa trên phương pháp luận chặt chẽ kết hợp giữa tìm kiếm tài liệu thuật toán và tham vấn chuyên gia liên tục. Ban đầu, nhóm nghiên cứu thiết lập các chiến lược tìm kiếm dựa trên các từ khóa liên quan đến trí tuệ nhân tạo, khung phân loại và rủi ro, áp dụng trên nhiều nền tảng cơ sở dữ liệu lớn bao gồm Scopus và các kho lưu trữ bản in trước như arXiv, SSRN, medRxiv. Quá trình này đã trả về 17.288 bản ghi duy nhất, tạo ra một khối lượng dữ liệu khổng lồ cần được sàng lọc. Nhằm tối ưu hóa hiệu quả, các tác giả đã sử dụng công cụ ASReview tích hợp thuật toán học máy (học chủ động – active learning) để hỗ trợ quá trình sàng lọc tiêu đề và tóm tắt. Thuật toán học chủ động này giúp liên tục đào tạo mô hình phân loại dự đoán độ liên quan của các bài báo, cho phép dừng quá trình đánh giá thủ công khi đạt đến những quy tắc dừng khắt khe để giảm tải công việc mà không bỏ sót dữ liệu quan trọng. Sau khi tiến hành đánh giá toàn văn 91 bài báo kết hợp với tham vấn chuyên gia và tìm kiếm xuôi ngược thông qua trích dẫn, nhóm đã chọn ra 74 tài liệu đáp ứng các tiêu chí nghiêm ngặt, trải dài qua các bài báo bình duyệt, bản in trước, tài liệu hội nghị và các báo cáo.
Tiếp theo, để xây dựng các khung phân loại hoàn chỉnh, nhóm nghiên cứu áp dụng phương pháp tiếp cận “tổng hợp khung phù hợp nhất” (best-fit framework synthesis), một phương pháp đan xen giữa diễn dịch từ trên xuống và quy nạp từ dưới lên. Quy trình này bắt đầu bằng việc trích xuất nguyên bản tất cả các diễn đạt rủi ro từ tài liệu vào một cơ sở dữ liệu động. Nhóm nghiên cứu chọn ra một bộ khung phân loại xuất sắc hiện có làm cơ sở ban đầu (phiên bản v1), sau đó tiến hành mã hóa dữ liệu đã trích xuất vào hệ thống này. Đối với những rủi ro không thể phân loại theo khung ban đầu, các nhà nghiên cứu tiến hành phân tích chủ đề phụ trợ để xác định các mẫu hình mới, từ đó trực tiếp cập nhật, mở rộng các tiêu chí và cấu trúc của danh mục, tạo ra các phiên bản tiếp theo cho đến khi toàn bộ 1.725 rủi ro đều được lập bản đồ một cách hoàn hảo. Quá trình mã hóa này được đối chiếu với nguyên tắc của lý thuyết hiện thực (grounded theory) nhằm duy trì độ chính xác tối đa đối với sự phân loại nguyên thủy của tác giả gốc, hạn chế việc người mã hóa áp đặt các suy diễn chủ quan.
4 – KẾT QUẢ NGHIÊN CỨU
Sự tổng hợp toàn diện từ nghiên cứu đã tạo ra một bộ cơ sở dữ liệu rủi ro vĩ đại gồm 1.725 rủi ro và lĩnh vực phụ riêng biệt được định vị từ 74 khung lý thuyết khác nhau. Kết quả phân tích qua lăng kính của Phân loại Nguyên nhân đã chỉ ra những mô hình đáng ngạc nhiên về nhận thức rủi ro: trái với giả định chung thường đổ lỗi cho công nghệ, các quyết định của con người chiếm tỷ trọng gây ra rủi ro (38%) gần như tương đương với các rủi ro phát sinh từ các thuộc tính nội tại của hệ thống AI (42%). Xét về mục đích hành động, tỷ lệ rủi ro phân bổ một cách đồng đều giữa kết quả cố ý theo đuổi mục tiêu (35%) và những hệ lụy vô ý ngoài mong muốn (35%). Tuy nhiên, kết quả đáng chú ý nhất ở mảng nguyên nhân là sự mất cân đối về mặt thời gian: các khung phân loại hiện tại dành sự tập trung áp đảo (62%) cho các rủi ro xuất hiện sau khi triển khai hệ thống, trong khi các rủi ro ở giai đoạn cốt lõi trước triển khai (chẳng hạn như quá trình đào tạo mô hình) lại bị ngó lơ đáng kể khi chỉ chiếm 13%.
Khi đối chiếu với Phân loại Miền, nghiên cứu phơi bày sự rời rạc và thiếu toàn diện nghiêm trọng giữa các khung tài liệu đang lưu hành. Một khung rủi ro trung bình thường chỉ có khả năng nhận dạng khoảng 8 trong tổng số 24 lĩnh vực phụ được hệ thống kho lưu trữ ghi nhận. Trong khi một số miền mang tính truyền thống như độ an toàn của hệ thống AI, các giới hạn công nghệ hay tác hại đối với kinh tế xã hội và môi trường thường xuyên góp mặt trong hơn 75% các danh mục phân loại hiện hành, thì nhiều khía cạnh rủi ro quan trọng lại vắng bóng. Các lĩnh vực chuyên sâu hoặc mang tính tương lai cao như quyền và phúc lợi của hệ thống AI chỉ xuất hiện lác đác trong khoảng 3% tổng số tài liệu, và rủi ro từ cấu trúc hệ thống đa tác nhân cũng chỉ chiếm tỷ lệ nghèo nàn là 7%. Những con số thống kê này đóng vai trò như một hồi chuông cảnh báo, cho thấy các hệ thống phân loại phân tán hiện nay chỉ đang cung cấp các lát cắt mang tính bộ phận, để ngỏ những điểm mù khổng lồ khiến việc đánh giá rủi ro chưa đáp ứng được sự bùng nổ của các mô hình AI có tính tự chủ cao.





