Tạo tập dữ liệu toàn quốc về các loại tòa nhà dân cư bằng phương pháp học máy
Generating a Nationwide Residential Building Types Dataset Using Machine Learning
| Tác giả | Kristina Dabrock
Jens Ulken Noah Pflugradt Jann Michael Weinand Detlef Stolten |
| Ngày đăng tải | 24/02/2025 |
| DOI | 10.1016/j.buildenv.2025.112782 |
| Nguồn bài nghiên cứu | Science Direct |
| Từ khóa | Học máy XGBoost
Loại hình tòa nhà TABULA Dữ liệu tòa nhà Trạng thái cải tạo |
1 – GIỚI THIỆU
Sự thiếu hụt dữ liệu tòa nhà chi tiết là một trở ngại lớn trong việc xây dựng các khuyến nghị cụ thể nhằm khử carbon trong lĩnh vực xây dựng. Để giải quyết vấn đề này, nghiên cứu này đề xuất một phương pháp tạo tập dữ liệu dựa trên các mô hình tòa nhà tiêu chuẩn hóa cho tất cả các tòa nhà dân cư tại Đức.
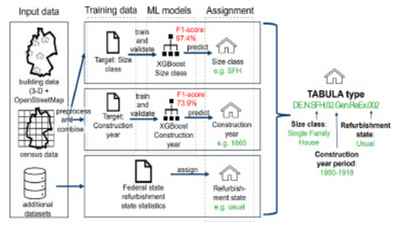
Một mô hình học máy XGBoost được sử dụng để dự đoán kích thước và năm xây dựng của từng tòa nhà. Trạng thái cải tạo của tòa nhà được xác định dựa trên số liệu thống kê cấp tiểu bang. Từ đó, các tòa nhà được gán vào các nhóm loại hình TABULA, một hệ thống phân loại tòa nhà phổ biến.
Dữ liệu huấn luyện được thu thập từ dữ liệu thống kê dân số của Đức và được tăng cường với các đặc điểm hình thái học của tòa nhà, thông tin khu dân cư và dữ liệu kinh tế – xã hội. Mô hình đạt độ chính xác 97.4% trong dự đoán kích thước tòa nhà và 73.9% trong dự đoán năm xây dựng, cho thấy mức độ tương thích cao với số liệu chính thức. Tuy nhiên, mô hình có xu hướng quá đại diện cho các nhóm loại hình phổ biến, điều này ảnh hưởng đến tính cân bằng của dữ liệu.
Tập dữ liệu kết quả cung cấp thông tin chi tiết về từng tòa nhà, có thể dùng để phân tích nhu cầu năng lượng, đề xuất các biện pháp cải tạo và hoạch định chính sách khử carbon, giúp hỗ trợ quá trình chuyển đổi năng lượng trong lĩnh vực xây dựng.
2 – MÔ TẢ HỆ THỐNG
Hệ thống được nghiên cứu dựa trên dữ liệu tòa nhà dân cư tại Đức, bao gồm thông tin về kích thước, năm xây dựng và trạng thái cải tạo. Các loại hình tòa nhà được phân loại theo hệ thống TABULA, trong đó bao gồm các dạng: nhà đơn lập (SFH), nhà liền kề (TH), chung cư (MFH) và khối căn hộ (AB).
Dữ liệu đầu vào cho mô hình được lấy từ nhiều nguồn khác nhau như OpenStreetMap, dữ liệu thống kê dân số, dữ liệu hình thái học của khu vực và các thông tin kinh tế – xã hội. Hệ thống cũng tính toán các đặc điểm như hình dạng mái, số tầng, diện tích tòa nhà và cấu trúc khu dân cư, giúp cải thiện độ chính xác của mô hình dự đoán.
Mô hình sử dụng thuật toán XGBoost để huấn luyện và dự đoán, giúp xác định các đặc điểm quan trọng trong việc phân loại tòa nhà. Sau khi gán nhãn TABULA, mỗi tòa nhà được liên kết với các thông số năng lượng như mức tiêu thụ nhiệt, hệ số cách nhiệt và diện tích cửa sổ, cung cấp một cơ sở dữ liệu mạnh mẽ cho các phân tích liên quan đến năng lượng.
3 – PHƯƠNG PHÁP NGHIÊN CỨU
Nghiên cứu sử dụng phương pháp học máy XGBoost để dự đoán hai yếu tố quan trọng của tòa nhà: kích thước và năm xây dựng. Các bước thực hiện bao gồm:
- Tạo tập dữ liệu huấn luyện:
- Dữ liệu từ thống kê dân số, OpenStreetMap và dữ liệu địa hình được tổng hợp để gán nhãn cho từng tòa nhà.
- Các đặc điểm như kích thước, số tầng, diện tích sàn và số hộ gia đình được sử dụng làm đầu vào cho mô hình học máy.
- Huấn luyện mô hình XGBoost:
- Mô hình được huấn luyện với dữ liệu nhãn về năm xây dựng và kích thước tòa nhà.
- Các kỹ thuật cân bằng dữ liệu được áp dụng để giảm thiểu sai lệch do sự phân bố không đồng đều của các loại hình tòa nhà.
- Gán nhãn TABULA:
- Sau khi dự đoán kích thước và năm xây dựng, mỗi tòa nhà được gán nhãn vào một nhóm TABULA tương ứng.
- Dữ liệu bổ sung về trạng thái cải tạo được tích hợp dựa trên thống kê cấp tiểu bang.
- Kiểm định mô hình:
- Độ chính xác của mô hình được kiểm tra bằng cách so sánh với dữ liệu thực tế từ thống kê dân số và dữ liệu chính thức về tòa nhà tại Đức.
- Sai lệch giữa tập dữ liệu kết quả và số liệu chính thức được phân tích để xác định các điểm cần cải thiện.
4 – KẾT QUẢ NGHIÊN CỨU
Mô hình học máy đạt độ chính xác 97.4% trong dự đoán kích thước tòa nhà và 73.9% trong dự đoán năm xây dựng. Các kết quả kiểm tra cho thấy:
- Nhóm nhà đơn lập (SFH) chiếm tỷ lệ lớn nhất, nhưng có xu hướng bị quá đại diện trong dữ liệu kết quả.
- Nhóm nhà chung cư (AB) có tỷ lệ bị đánh giá thấp hơn thực tế, do giới hạn của mô hình trong việc phân loại nhóm này.
- Các tòa nhà được xây dựng trong giai đoạn 1949–1979 có xu hướng bị quá đại diện, trong khi các tòa nhà hiện đại (sau năm 2000) ít hơn thực tế.
- Việc phân loại TABULA giúp xác định các yếu tố ảnh hưởng đến tiêu thụ năng lượng, tạo cơ sở cho các nghiên cứu về cải tạo và khử carbon trong ngành xây dựng.
Nghiên cứu cũng cho thấy rằng tập dữ liệu này có thể được sử dụng để đánh giá mức tiêu thụ năng lượng của tòa nhà, với độ chính xác cao so với thống kê chính thức. Tuy nhiên, một số cải tiến cần được thực hiện để cân bằng dữ liệu và giảm sai lệch giữa các nhóm tòa nhà.
5 – KẾT LUẬN
Nghiên cứu đã chứng minh rằng việc sử dụng học máy để phân loại và phân tích tòa nhà có thể giúp cải thiện đáng kể độ chính xác của các mô hình dự báo năng lượng. Bằng cách tạo một tập dữ liệu toàn quốc về các loại hình tòa nhà, nghiên cứu này cung cấp một công cụ mạnh mẽ để đánh giá nhu cầu năng lượng và phát triển các chiến lược khử carbon trong ngành xây dựng.
Dù đạt được kết quả khả quan, nghiên cứu cũng chỉ ra một số hạn chế, bao gồm sự mất cân bằng dữ liệu và hạn chế trong việc xác định trạng thái cải tạo của từng tòa nhà. Trong tương lai, cần có thêm các nghiên cứu để mở rộng mô hình cho các khu vực khác và cải thiện độ chính xác của dữ liệu TABULA.
Tập dữ liệu được công bố dưới dạng mã nguồn mở và có thể được sử dụng để phát triển các mô hình dự báo năng lượng, hỗ trợ các chính sách phát triển bền vững và tối ưu hóa chiến lược cải tạo tòa nhà.





